本期收录模型速览
生成模型是一种训练模型进行无监督学习的模型,即,给模型一组数据,希望从数据中学习到信息后的模型能够生成一组和训练集尽可能相近的数据。图像生成(Image generation,IG)则是指从现有数据集生成新的图像的任务。图像生成模型包括无条件生成和条件性生成两类,其中,无条件生成是指从数据集中无条件地生成样本,即p(y);条件性图像生成是指根据标签有条件地从数据集中生成样本,即p(y|x)。
图像生成也是深度学习模型应用比较广泛、研究程度比较深的一个主题,大量的图像库也为SOTA模型的训练和公布奠定了良好的基础。在几个著名的图像生成库中,例如CIFAR-10、ImageNet64、ImageNet32、STL-10、CelebA 256、CelebA64等等,目前公布出的最好的无条件生成模型有StyleGAN-XL、Diffusion ProjectedGAN;在ImageNet128、TinyImageNet、CIFAR10、CIFAR100等库中,效果最好的条件性生成模型则是LOGAN、ADC-GAN、StyleGAN2等。
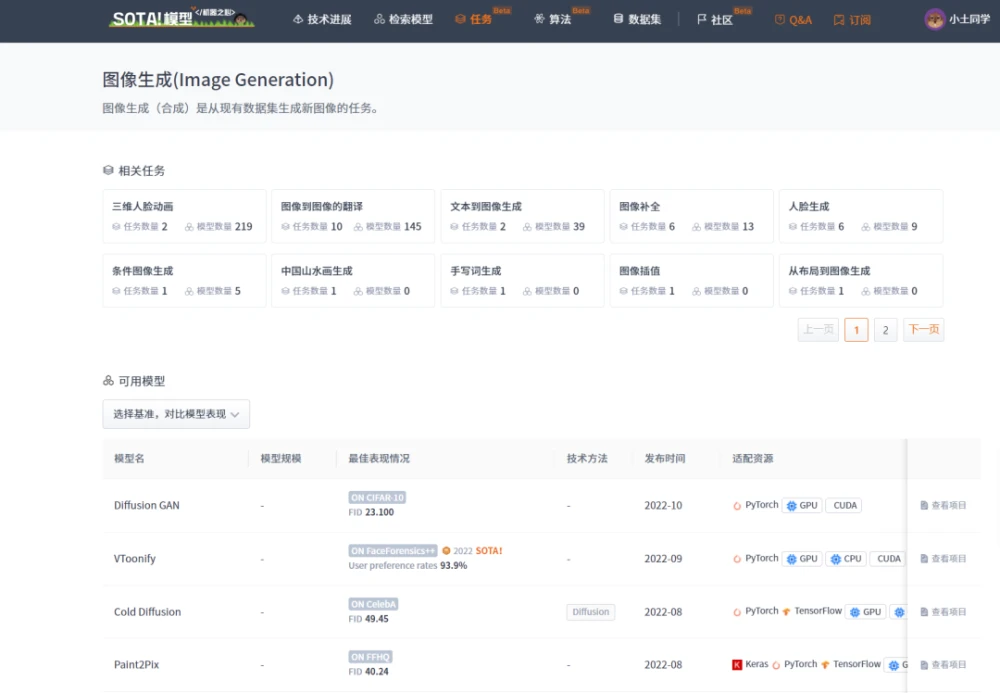
我们在这篇文章中介绍图像生成必备的TOP模型,从无条件生成模型和条件性生成模型两个类别分别介绍。图像生成模型的发展非常快,所以与其它几个topic不同,图像生成中必备的TOP模型介绍主要以近两年的SOTA模型为主。
条件性生成模型
WGAN
WGAN即Wasserstein GAN。GAN网络训练的重点在于均衡生成器G与鉴别器D:若鉴别器太好,loss不再下降,则生成器就学不到东西,也就无法继续提升生成图像的质量。所以在原始GAN的(近似)最优判别器下,生成器loss面临着梯度消失、梯度不稳定、对多样性与准确性惩罚不平衡导致的mode collapse等一系列问题。问题的根源是:
- 等价优化的距离衡量(JS散度)不合理;
- 生成器随机初始化后的生成分布很难与真实分布重叠。
WGAN就是为解决上述两个GAN的问题而提出的,即,引入Wasserstein距离衡量两个分布之间的Wasserstein距离,从而实现即使两个分布没有任何重叠,也可以反应他们之间的距离。由于Wasserstein距离相对KL散度与JS 散度具有优越的平滑特性,理论上可以解决梯度消失问题。WGAN最小化一个合理而有效的EM( Earth Mover)距离的近似值。
WGAN与原始GAN第一种形式相比,只改了四点:
- 鉴别器的最后一层中去掉了sigmoid,鉴别器要拟合的是Wasserstein距离,所以不是一个0或1的分类问题,而是回归问题,取值不限于0到1;
- 生成器和鉴别器的loss不取log;
- 每次更新鉴别器的参数之后把它们的值截断到不超过一个固定常数c,即令鉴别器的函数是一个Lipschitz函数,函数的导数小于某个固定的c值;
- 不使用基于动量的优化算法(包括momentum和Adam),推荐RMSProp。
与原始的GAN相比,WGAN的鉴别器D的作用是一个EM距离的计量器,因此鉴别器越准确,对生成器越有利,可以在训练一个Step时训练D多次,训练G一次,从而获得较为准确的EM距离估计。WGAN的算法流程如下述Algorithm 1。

当前 SOTA!平台收录 WGAN 共 96 个模型实现资源。
SAGAN
跟踪图像中复杂的几何轮廓需要long-range dependencies(长距离依赖),但是,卷积的特点就是局部性,受到感受野大小的限制,卷积的操作很难提取到图像中的这些长距离依赖。虽然可以通过加深网络或者扩大卷积核的尺寸的方法在一定程度上解决该问题,但是这会使卷积网络丧失了其参数和计算的效率优势。SAGAN聚焦的问题就是:如何找到一种能够利用全局信息的方法,具体的,SAGAN把 Attention 机制引入到 GANs 的图像生成当中。
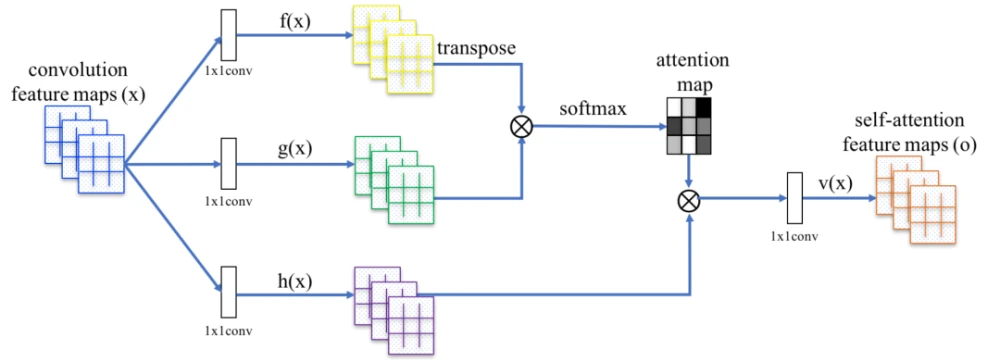
图1 SAGAN的自注意力模块。⊗表示矩阵乘法,对每一行进行softmax操作
SAGAN的架构如图1所示,其核心就是用带有自注意力的特征图去代替传统的卷积特征图,建模像素间的远距离关系,即在一层获取远距离的依赖关系而非多层卷积操作获得依赖关系。首先,图17中的f(x)、g(x)和 h(x)都是普通的 1x1 卷积,差别只在于输出通道大小不同(这是1x1 卷积的特性,可以通过控制1x1 卷积的通道数来实现特征通道的升维和降维。然后,将 f(x)的输出转置,并和 g(x)的输出相乘,再经过 softmax 归一化得到一个 attention map。最后,将得到的 attention map 和 h(x)逐像素点相乘,得到自适应注意力的特征图:
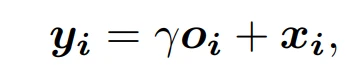
其中,γ是一个可学习的标量,初始化为0。γ允许网络首先依赖局部附近的线索,然后逐渐学会为非局部线索分配更大的权重。在SAGAN中,将自适应注意力模块同时应用于生成器和鉴别器,通过最小化 hinge version of the adversarial loss 以交替的方式进行训练。
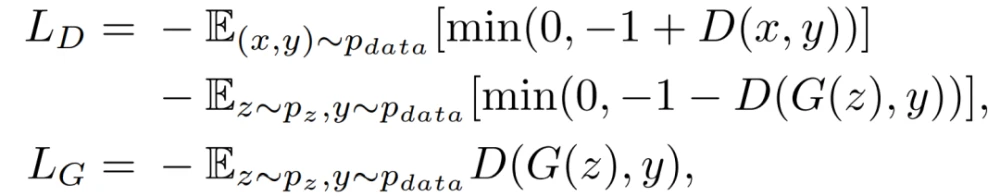
SAGAN当中提出了两种优化方式以实现稳定训练的 GANs,分别是Spectral Normalization与TTUR(Two Timescale Update Rule),前者稳定了训练和生成过程,后者平衡了D与G的训练速度。
- Spectral Normalization。SAGAN为D和G加入了谱范数归一化的方式,让D满足了1-lipschitz限制,同时也避免了G的参数过多导致梯度异常,使得整套训练较为平稳和高效。
- TTUR。在以前的工作中,鉴别器的正则化通常会减慢GAN学习过程。实际上,使用正则化鉴别器的方法通常在训练期间每个生成器需要多个更新步骤。本文建议专门使用TTUR来补偿正则化鉴别器中慢学习的问题,使得对于每个鉴别器步骤使用更少的生成器步骤成为可能。
当前 SOTA!平台收录SAGAN共 43 个模型实现资源。
BIG-GAN
BIG-GAN希望应对的是从像ImageNet这样的复杂数据集成功生成高分辨率、多样化的样本的问题。BIG-GAN的基线方法是SAGAN,它使用hinge损失,类别条件BatchNorm向G提供类别信息,用投影向D提供类别信息,通过调整网络提高GAN模型生成图像的真实性和多样性,同时,保证GAN模型的稳定性。
BIG-GAN的很多参数都是在SAGAN上调整的,batch size的大小为原来的8倍,将隐藏层的变量数量扩充到4倍以后,进行训练获得了很好的图片生成的效果。优化设置遵循SAGAN(特别是在G中使用谱范数)的修改,BIG-GAN将学习速率减半,在训练一个Step时训练D两次,训练G一次。
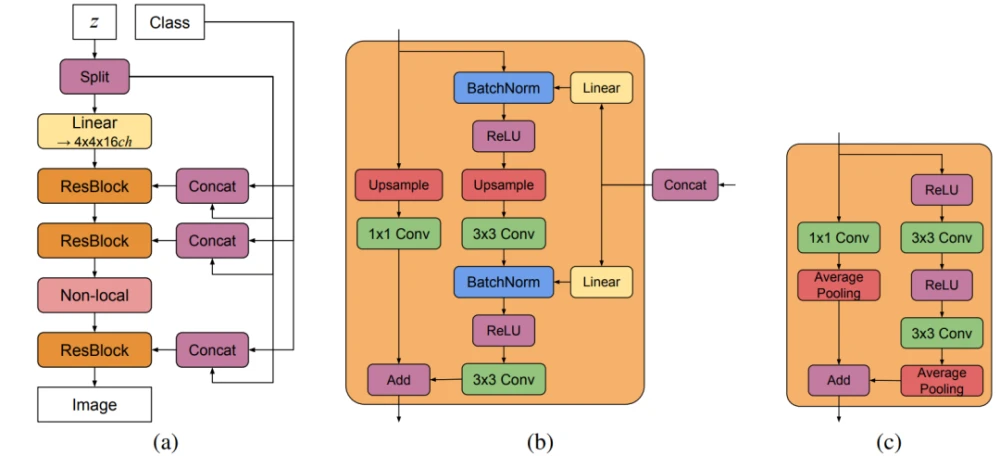
图2. (a) BigGAN的典型架构;(b) G中的残差块(ResBlock up);c)D中的残差块(ResBlock down)
由图2,在G中使用单一的共享类别嵌入,并跳过潜在向量z的连接(skip-z)。特别是,采用分层的潜在空间,使潜在向量z沿着其通道维度被分割成大小相等的块(图18的示例中是20-D),每个块被连接到共享类别嵌入,并作为调节向量传递给相应的残差块。每个块的调节被线性投影,以产生块的BatchNorm层的每个样本的增益和偏置。偏置投影以零为中心,而增益投影以1为中心。由于残差块的数量取决于图像分辨率,128×128图像的z全维度为120,256×256为140,而512×512的图像为160。
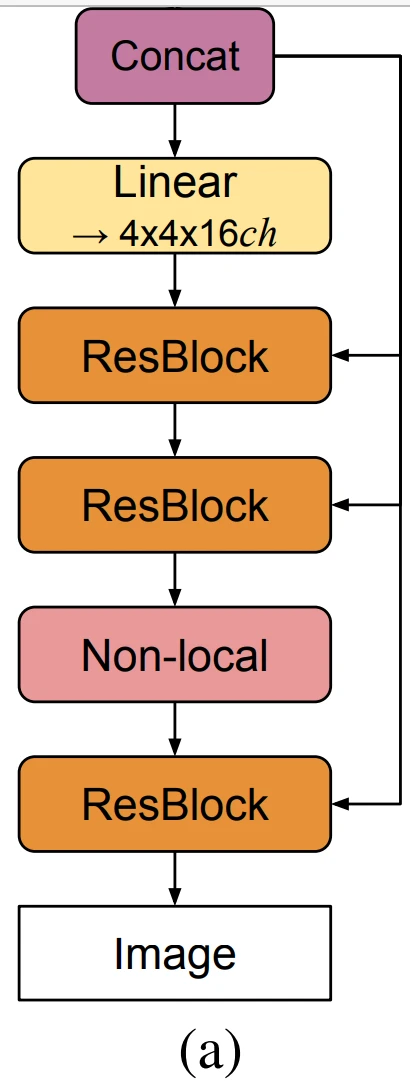
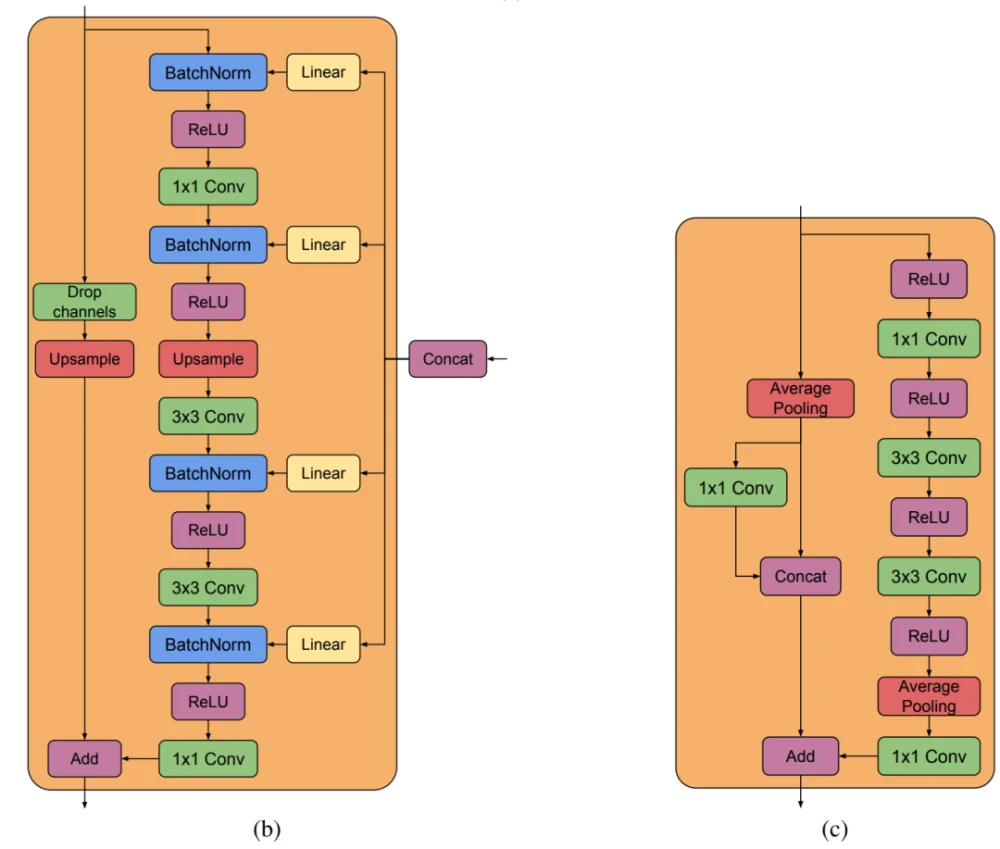
图3. (a) BigGAN-deep的典型架构。(b) G中的一个残差块(ResBlock up)。(c)D中的一个残差块(ResBlock down)
BigGAN-deep模型(图3)在几个方面与BigGAN不同。它使用了一个更简单的skip-z conditioning的变体:不是先将z分割成块,而是将整个z与类别的嵌入相连接,并通过skip connection将得到的向量传递给每个残差块。BigGAN-deep基于带有瓶颈的剩差块,其中包含两个额外的1×1卷积:第一个在3×3卷积之前将通道的数量减少了4倍;第二个产生所需的输出通道数量。在BigGAN中,每当需要改变通道数量时,都会在skip connection中使用1×1的卷积,而在BigGAN-deep中,使用了一种不同的策略,旨在保持整个skip connection的特性。在G中,如果需要减少通道的数量,只需保留第一组通道,并放弃其余的通道以产生所需的通道数量。在应该增加通道数量的D区,将输入通道不加扰动地通过,并与1×1卷积产生的剩余通道串联起来。就网络配置而言,鉴别器是发生器的精确反映。每个分辨率有两个块(BigGAN使用一个),因此BigGAN-deep比BigGAN深四倍。
当前 SOTA!平台收录 BIG-GAN 共 29 个模型实现资源。
CSGAN
CSGAN是一种新的周期合成生成对抗网络,主要服务的目标是image-to-image transformation,在一个域合成图像和另一个域循环图像之间使用了一种新的目标函数循环合成损失(CS)。
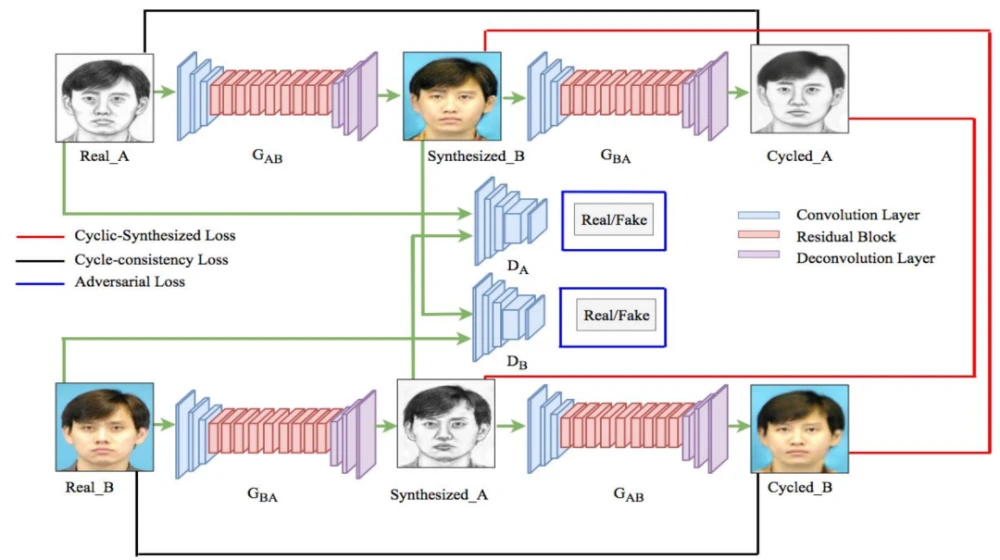
图4. CSGAN的网络结构,用于图像-图像转换。本文提出的循环-合成损失是为了利用两个图像域中合成图像和循环图像之间的关系。因此,除了对抗性损失和循环一致性损失之外,还使用了循环合成损失来训练网络。对抗性损失用蓝色的矩形表示,它是在1)生成器G_AB和鉴别器D_B,以及2)生成器G_BA和鉴别器D_A之间计算的。循环一致性损失用黑色表示,为真实图像和循环图像之间的L1损失。循环-合成损失以红色显示,为合成图像和循环图像之间的L1损失
如图4所示,CSGAN方法的总体工作是将图像R_A从域A转化为B,并将其交给生成器网络G_AB,从而得到合成的图像S_ynB。将合成的图像S_ynB从域B转化为原域A,并将其交给生成器网络G_BA,得到循环的图像C_ycA。以同样的方式,来自B域的真实图像R_B首先被转换到A域作为合成图像S_ynA,然后通过使用生成器网络G_BA和G_AB分别转换回B域作为循环图像C_ycB。鉴别器网络D_A用于区分真实图像R_A和合成图像S_ynA。同样地,鉴别器网络D_B用于区分真实图像R_B和合成图像S_ynB。为了生成最接近真实图像的合成图像,它们之间的损失要最小化。这就意味着需要有高效的损失函数。CSGAN引入了一种新的损失函数循环合成损失(CS loss),它可以在降低伪影的情况下提高结果的质量:
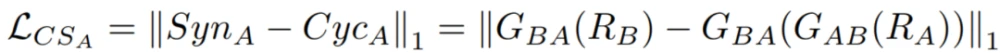
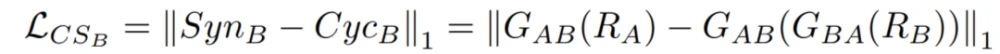
其中,L_CSA是A域(即S_ynA和C_ycA之间)的循环合成损失,L_CSB是B域(即S_ynB和C_ycB之间)的循环合成损失。CSGAN方法的目标函数(L)结合了所提出的Cyclic-Synthesized损失与现有的Adversarial损失和Cycle-consistency损失,如下所示:
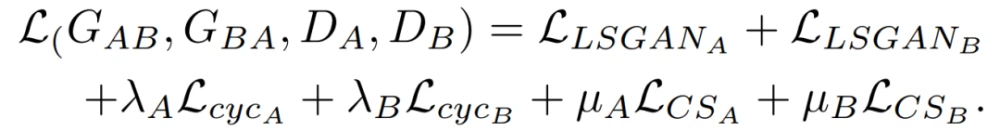
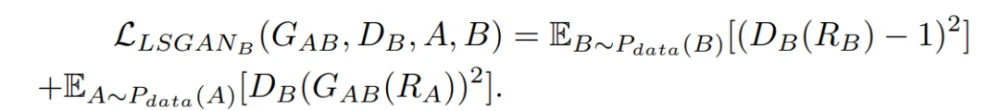
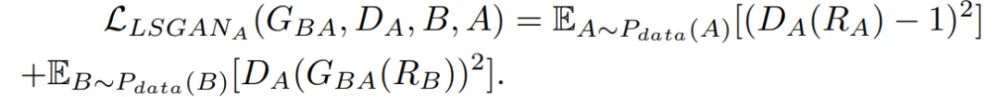
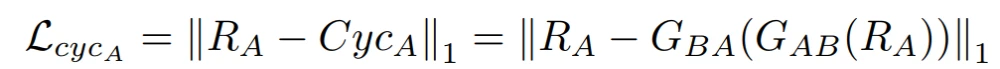
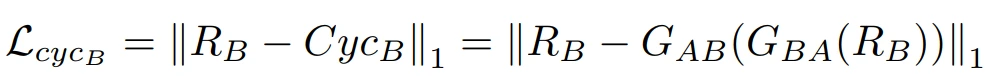
CSGAN的生成器网络由3个卷积层、9个残差块和3个去卷积层组成,使用实例归一化,而不是批量归一化。源域中256×256维的输入图像输入到网络。该网络通过一系列的下卷积和上卷积,将256×256的图像保留在另一个域中。鉴别器网络是一个70×70的PatchGAN,由4个卷积层组成,每个卷积层都是convolution-instance-norm-swing-ReLU的序列,然后是1个卷积层,产生1维的输出。鉴别器网络采用256×256维度的图像,输出为表征图像真假的概率(即0代表假,1代表真)。斜率为0.2的Leaky ReLUs被用作鉴别器网络的激活函数。
当前 SOTA!平台收录 CSGAN 共 1 个模型实现资源。
LOGAN
LOGAN是一种受CSGAN启发的潜在优化(latent optimisation),核心思想是加强鉴别器和生成器之间的交互来改善对抗性。如图5,首先,令潜在变量z通过生成器和鉴别器进行前向传播。然后,用生成器损失(红色虚线箭头)的梯度来计算改进的z’。在第二次前向传播中,使用优化后的z’。其后,引入潜在优化计算鉴别器的梯度。最后,用这些梯度来更新模型。
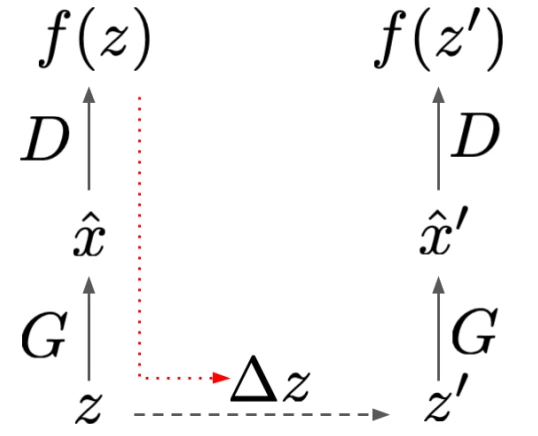
图5. LOGAN示意图。首先计算一个通过G和D的前向传递,有一个 sampled latent z,然后,使用来自生成器损失的梯度(红色虚线箭头)来计算一个改进的latent z’。在第二次正向传递中使用这个改进的latent后,通过latent优化计算出鉴别器的梯度,返回到模型参数θ_D、θ_G中
LOGAN的完整计算过程见下述Algorithm 1:

当前 SOTA!平台收录 LOGAN 共 2 个模型实现资源。
UNet-GAN
GANs面临的主要挑战之一是:生成全局和局部一致的图像,使得其物体形状和纹理与真实图像无法区分。UNet-GAN是一个致力于解决这一问题的基于U-Net的替代性鉴别器架构。基于U-Net的架构允许向生成器提供 per-pixel反馈,同时通过提供全局图像反馈,保持生成图像的全局一致性。在鉴别器的per-pixel 响应支持下,进一步提出了一种基于CutMix数据增强的per-pixel 一致性正则化技术,鼓励U-Net鉴别器更加关注真实和虚假图像之间的语义和结构变化。
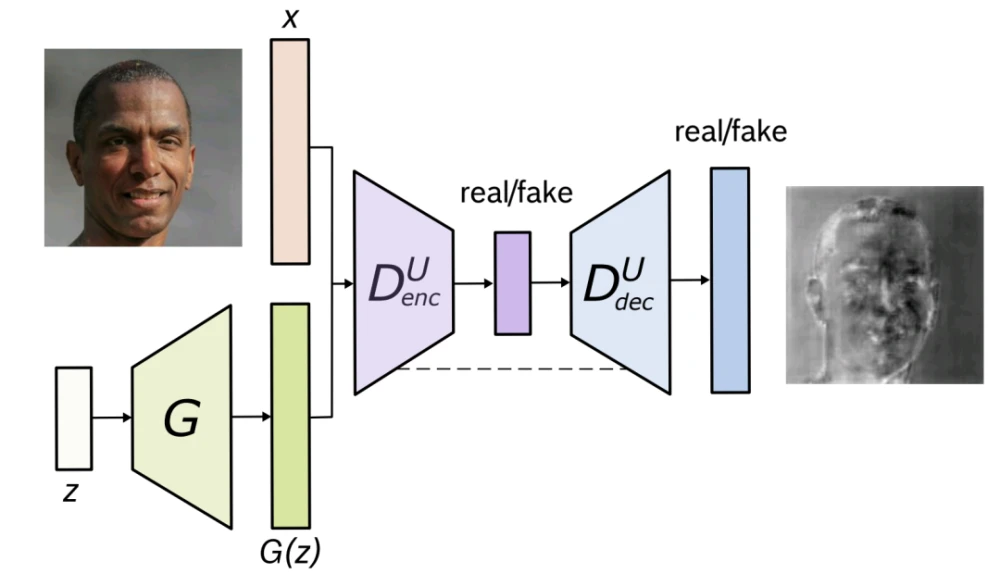
图6. U-Net GAN。U-Net鉴别器在全局和局部per-pixel层面对输入图像进行分类。由于编码器和解码器之间的skip connections(虚线),输出层的通道既包含高层次信息也包含低层次信息。解码器输出中较亮的颜色表征鉴别器对像素是真实的信任程度(颜色越暗表征越怀疑是假的)
Unet-GAN通过重复使用原鉴别器分类网络的构件作为编码器部分,以及生成器网络的构件作为解码器部分,来扩展鉴别器形成一个U-Net,即,鉴别器现在由原来的下采样网络和一个新的上采样网络组成。这两个模块通过一个瓶颈连接,以及,从编码器和解码器模块复制和串联特征图的skip connections。将分类器表征为D^U。原始的D(x)将输入的图像x分类为真实和虚假,而U-Net鉴别器D^U(x)则在per-pixel层面额外执行这种分类处理,将图像x分割为真实和虚假区域,同时还有来自编码器的x的原始图像分类。这使鉴别器能够学习真实和虚假图像之间的全局和局部差异。把鉴别器的原始编码器模块称为(D^U)_enc,把引入的解码器模块称为(D^U)_dec。现在,新的鉴别器损失可以通过从(D^U)_enc和(D^U)_dec中获取决策来计算:
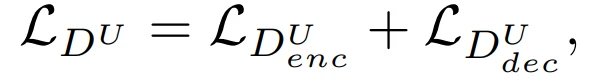
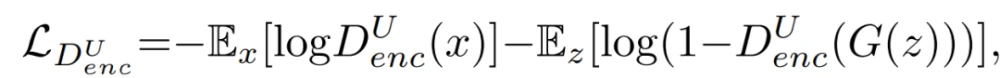
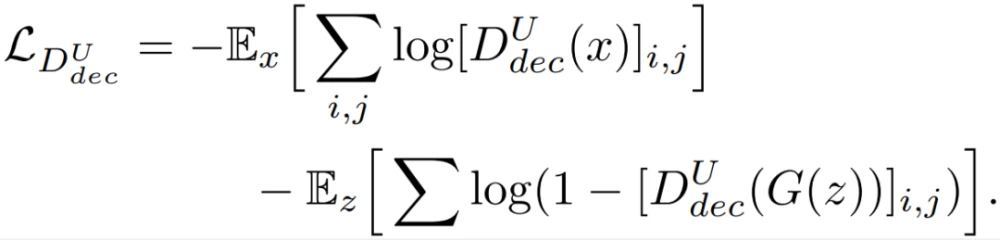
(D^U)_dec的这些per-pixel输出是基于来自高级特征的全局信息,通过瓶颈的上采样过程实现的,以及来自低级特征的更多局部信息,由编码器网络中间层的skip-connection介导的。最终生成器的目标函数为:
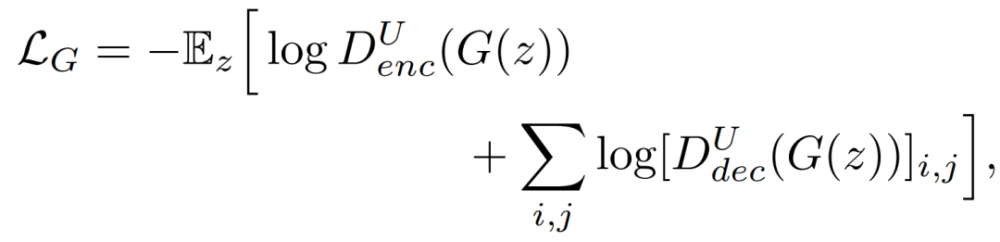
进一步,提出了D^U鉴别器的一致性正则化,鼓励解码器模块(D^U)_dec在真实和虚假样本的CutMix转换下输出等值预测值。图7中展示了CutMix的增强策略和D^U的预测。

图7. CutMix增强和U-Net鉴别器对CutMix图像的预测的可视化。第一行:真实和虚假的样本。第二行和第三行:采样的真/假CutMix比率r和相应的二进制掩码M(颜色代码:白色为真,黑色为假)。第四行:从真实和虚假样本中生成的CutMix图像。第5行和第6行:相应的真/假D^U的分割图及其预测的分类分数
具体的,通过将x和G(z)∈RW×H×C与掩码M混合,为鉴别器D^U合成一个新的训练样本x˜
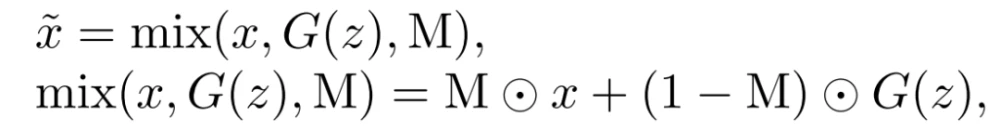
鉴于CutMix操作,训练鉴别器通过在鉴别器目标中引入一致性正则化损失项,以提供一致的per-pixel预测:
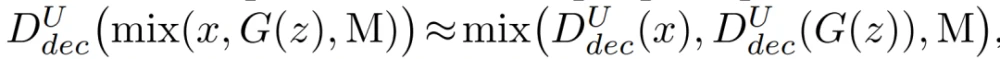
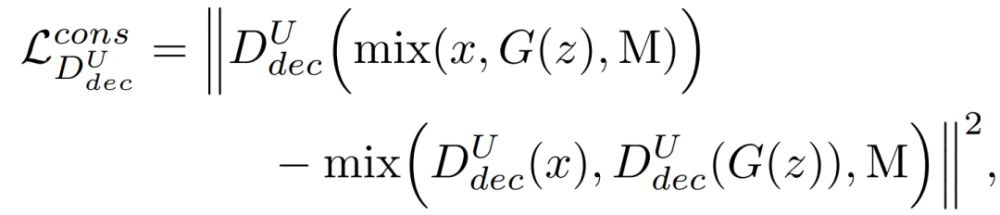
最终生成器的目标函数为:
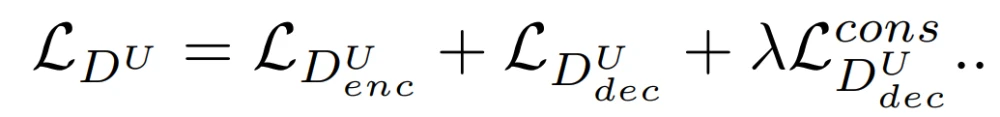
当前 SOTA!平台收录UNet-GAN共 1 个模型实现资源。
IC-GAN
GAN 有着神经网络模型所共有的致命缺点,就是具有局限性,通常只能生成与训练数据集密切相关的物体或场景的图像。Facebook AI Research 为了解决这个问题,提出了IC-GAN,可以生成逼真的、没有见过的图像组合。研究人员从核密度估计(kernel density estimation, KDE)技术中得到启发,引入了一种非参数化方法来建模复杂数据集的分布。KDE是一种非参数密度估计器,以参数化核的混合形式对每个训练数据点周围的密度进行建模。IC-GAN可以看作是一种混合密度估计器,其中每个分量都是通过对训练实例进行条件化得到的。
IC-GAN 将数据流形划分为由数据点及其最近邻描述的重叠邻域的混合物,IC-GAN模型能够学习每个数据点周围的分布。通过在条件实例周围选择一个足够大的邻域,可以避免将数据过度划分为小的聚类簇。当给定一个具有M个数据样本的未标记数据集的嵌入函数f,首先使用无监督或自监督训练得到f来提取实例特征(instance features)。然后使用余弦相似度为每个数据样本定义k个最近邻的集合。使用生成器隐式模拟条件分布p(x | h_i) 时,生成器从单位高斯先验z~N(0, 1)变换样本从条件分布中抽取样本x,其中h_i是从训练数据中抽取的实例x_i的特征向量。
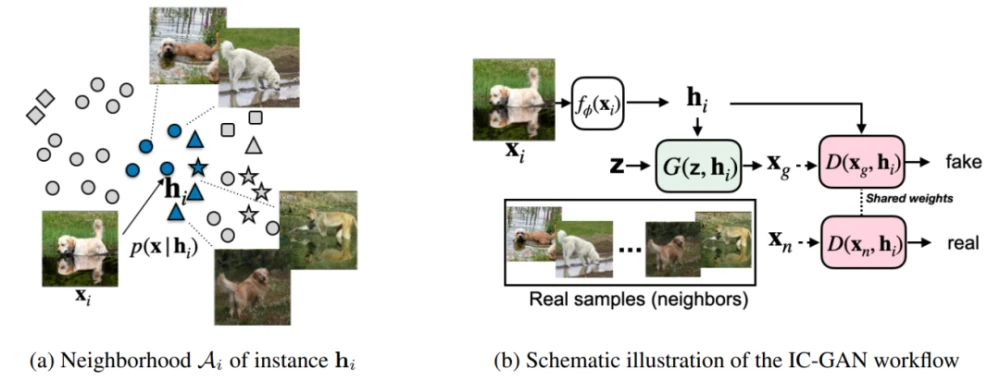
图8. IC-GAN。(a) 生成器的目标是生成与h_i的邻域相似的现实图像,在嵌入空间中使用余弦相似度定义。图中显示了七个邻居中的五个。请注意,同一邻域的图像可能属于不同的类别(被描述为不同的形状)。(b) 以实例特征h_i和噪声z为条件,生成器产生一个合成样本x_g。生成的样本和真实样本(h_i的邻居)被送入鉴别器,鉴别器以相同的h_i为条件
在IC-GAN中,采用对抗式方法来训练生成器,因此可以联合训练生成器和鉴别器,鉴别器用来区分h_i的真实相邻节点和生成的相邻点。对于每个h_i,真实邻居都从A_i中均匀采样。生成器 G和鉴别器 D都参与了一个两人最小-最大博弈,在博弈中,二者试图找到目标的纳什均衡的等式。
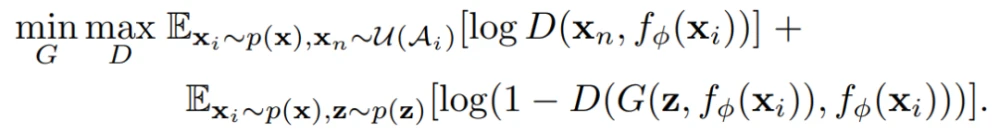
在训练IC-GAN时,使用所有可用的训练数据点来微调模型。在推理时,与KDE等非参数密度估计方法一样,IC-GAN的生成器也需要实例特征,这些特征可能来自于训练分布或不同的分布。
并且这种方法可以扩展到具有类别条件(class condition)的生成上。通过在类别标签y上添加一个额外的生成器和鉴别器,可以让IC-GAN 用于有类别条件的生成。IC-GAN 通过向生成器和鉴别器提供实例的表示作为额外的输入,并通过使用实例的邻居作为鉴别器的真实样本,学习对数据点(也称为实例)的邻域的分布建模。与对离散簇索引进行条件处理不同,对实例表示进行条件处理自然会导致生成器为相似实例生成相似样本。并且一旦训练完成,IC-GAN可以通过在推理时简单地交换条件实例,轻松地迁移到训练期间未看到的其他数据集。
作者在文章中是基于BigGAN和StyleGAN2实现的IC-GAN,同时扩展了它们的架构来处理引入的实例条件。当使用BigGAN作为基础架构时,IC-GAN用全连接层来替换生成器和鉴别器中的类别嵌入层。生成器中的全连接层的输入大小为2,048(对应于特征提取器f_θ的维数)和一个可以调整的输出大小o_dim。鉴别器中的全连接层具有一个可变的输出大小n_dim来匹配中间无条件鉴别器特征向量的维数。对于类别条件的IC-GAN,同时使用类别嵌入层以及与实例条件反射相关联的全连接层。将类别嵌入(维度c_dim=128)和实例嵌入(维度o_dim=512)连接起来。
当使用StyleGAN2作为基础架构时,将生成器中的输出维数512的全连接层替换类别嵌入层。替换鉴别器中的类别嵌入的全连接层是大小可变的。在这种情况下,实例特征与StyleGAN2的映射网络输入处的噪声向量连接起来,为生成器创建一个style vector。当涉及到鉴别器时,映射网络只输入提取的实例特征,以获得一个modulating vector,该向量乘以每个块上的内部鉴别器表示。所有实例特征向量h_i在计算邻域和用作GAN的条件反射之前都用l2范数进行归一化处理。
当前 SOTA!平台收录IC-GAN 共 1 个模型实现资源。
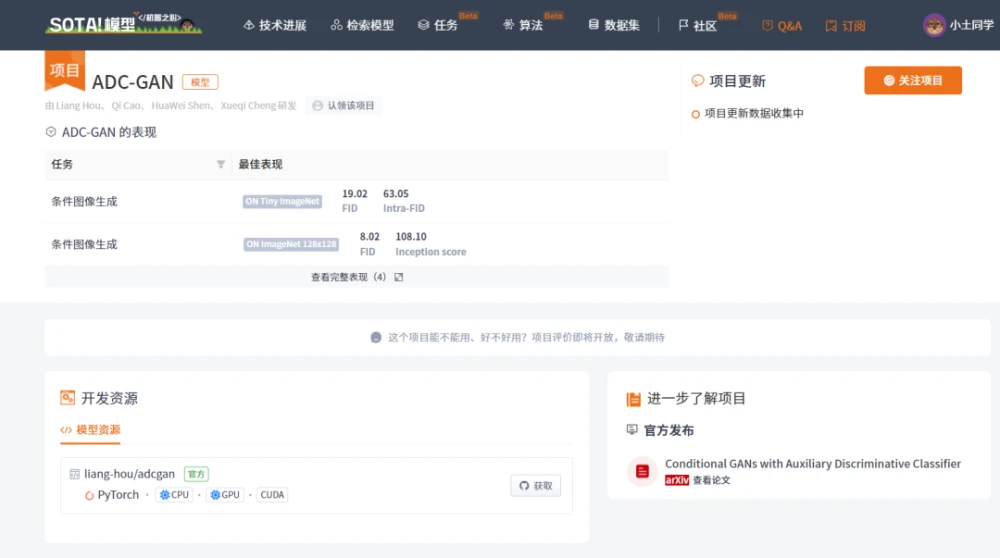
ADC-GAN
条件生成模型(Conditional generative models )学习数据和标签的基本联合分布,以实现条件数据的生成。其中,辅助分类器生成式对抗网络(auxiliary classifier generative adversarial network ,AC-GAN)已被广泛使用,但存在着生成样本的类内多样性低的问题。原因是AC-GAN的分类器与生成器无关,因此不能为生成器提供接近联合分布的信息指导,导致条件熵的最小化降低了类内多样性。ADC-GAN的目标是解决上述问题,具体来说,所提出的辅助判别分类器通过辨别真实数据和生成的数据的类别标签而具备生成器感知特性( generator-aware )。
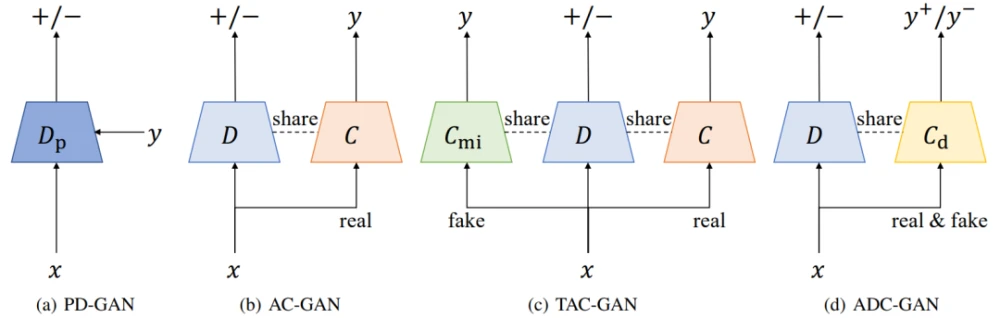
图9 cGAN、AC-GAN、TAC-GAN和ADC-GAN的鉴别器/分类器的说明。符号+/-表示GAN标签(真实或虚假),y是数据x的类别标签。ADC-GAN与cGAN不同,它明确预测了标签,与AC-GAN和TAC-GAN不同的是,分类器C_d也区分真实和生成,就像鉴别器一样
使分类器能够对具有不同类别标签的真实数据和生成的数据进行分类,建立一个鉴别性分类器Cd : X → Y+ ∪ Y- (Y+代表真实数据,Y-代表生成的数据),以鉴别性地识别真实和生成样本的标签。鼓励生成器产生可分类的真实数据,而不是可分类的虚假数据。ADC-GAN的鉴别器、鉴别分类器和生成器的目标函数被定义为:
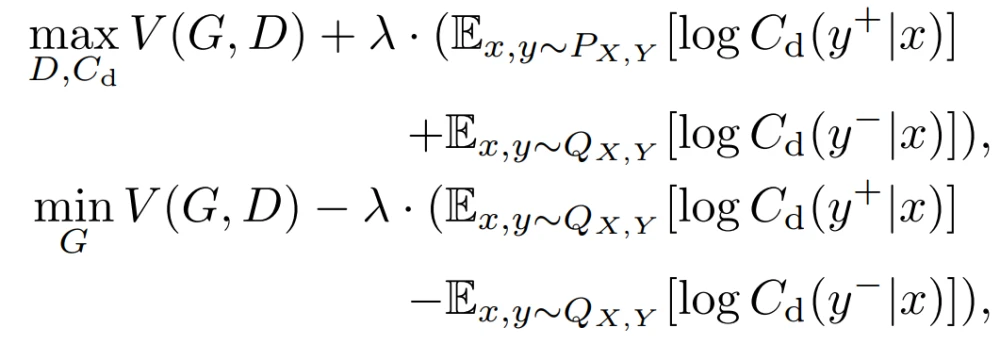
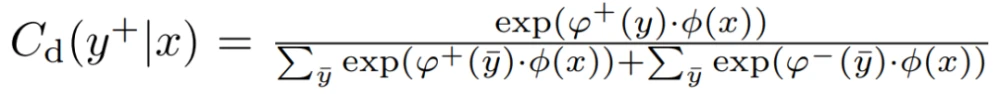
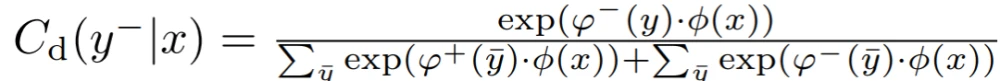
其中,C_d表示数据x被判别性分类器同时归类为标签y和真假的概率。φ : X → Rd是一个特征提取器,与原始鉴别器共享(D = σ ◦ ψ ◦ φ,具有线性映射ψ : Rd → R和sigmoid函数σ : R → [0, 1]),ϕ+ : Y → Rd和ϕ- : Y → Rd捕获负责真实和生成数据的标签的可学习嵌入。log C_d(y+|x)的最大化鼓励生成器只生成少数标签一致的数据,促进了保真度,但失去了生成样本的多样性。另一方面,log C_d(y-|x)的最小化鼓励生成器不合成典型的标签一致的数据,增加多样性,但可能降低生成样本的保真度。
当前 SOTA!平台收录 ADC-GAN 共 1个模型实现资源。